What follows is a very qualitative, non technical discussion about how data is transmitted between computers across the Internet through TCP/IP. We will get slightly more precise and technical in the next section, for now let us address some elementary concepts.
A very basic rule of data (files, e-mails, web pages et-cetera) transmission across the Internet, and actually a distinctive feature of the TCP/IP protocols used to move data, is that data is never transmitted “as such”. Instead, it is subdivided in so-called “packets” before transmission. The number of the packets depends on the size of the data. For simplicity, let us think about the transmission of a text file. The bigger the file, the more packets will be needed to “represent” the file.
If we picture a file as a train, the packets would be the individual wagons. Big train: several wagons, small train: few, maybe just one wagon.
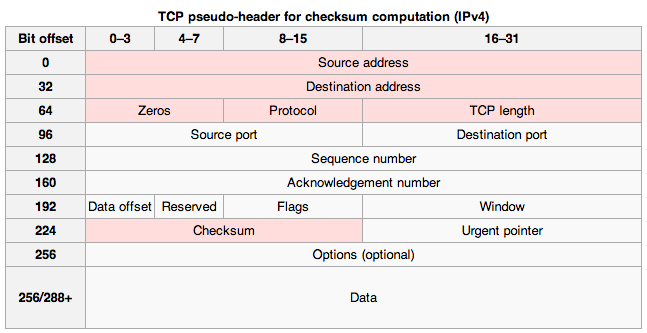
Each packet is like an envelope sent by normal mail, with the actual data, part of the original file, inside. Outside, we have information that will allow TCP/IP to process the packet by extracting and merging it’s inside data with the data from the other packets from the same file, in the correct order, in order to rebuild the file from it’s packets. A scheme of a TCP/IP packet is shown in Figure 1-1-1)
Each packet, or envelope if we follow on the previous example, contains the following information: the source of the data (sender), the destination of the data (receiver), information on the source file and on the position of the packet in this file (say packet 3 of 123 from file X). With this information, once all the packets for a file have reached the intended destination, they can be used by TCP/IP to rebuild the original file.
We could summarize the journey of a file such as an e-mail message or a web page, from computer A to computer B, as follows.
File in computer A –> Subdivided in packets by TCP/IP –> Packets travel, individually, to destination –> TCP/IP “remounts” the packets to re-create the original file in computer B –>File in computer B
You may notice, in the scheme above, that the fact that packets travel individually is underlined. As we mentioned, communication paths (most often constituted by physical wires) between computer A and computer F (Figure 1-1) on the Internet are often redundant. Also, these paths are often not direct (unless A and F are in the same room or the same building), but rather contain a number or “relays”. That is, in order for data to travel from A to F, they might be relayed through B, C, and D (Figure 1-1). Physically, on the hardware level, there relays are constituted by Routers. As the name implies, routers allow packets to find the best route between two computers that do not belong to the same network. Data are generally relayed through several such routers before they reach their final destination.
The crucial thing to understand here, is that at any given time (we re talking about milliseconds), the best route between 2 computers may change. Routers are able to determine, at the moment of sending a particular packet, the best route at this time. When sending the next packet, the best route may be different. Therefore, each packet from the same file could take a different route in order to reach the intended destination.
While files are being transferred between 2 PCs, a dialogue goes on between the TCP/IP software of the sender computer and the TCP/IP software on the receiving computer, aimed at ensuring that the file transfer will be successful. If for instance a packet is missing on the receiving side, TCP/IP from this computer will send a message to TCP/IP on the sender computer, asking to re-send a particular packet (this is specifically true for the TCP protocol – other protocols such a UDP work differently). The dialogue will end when all the packets have reached the destination.
Although this packet organization might seem complex, it has a number of advantages, with respect to an hypothetical model based on sending entire unfragmented files. First, with a “send entire file” model, if something goes wrong, you have to start over. Bandwidth is limited, so this would be highly inefficient and would clutter the network. With packets, if something goes wrong with a packet, you just have to re-send this packet, not the whole file. This illustrates well the concept of a “fault-tollerant” system. Second, maybe sending a small file, could take a very long time, if there is a big file being transferred “before it”. Let’s go back to the image of the train, in which the packets are the wagons. The bandwidth is finite (imagine you only have one rail). In order to send a small one packet file (a one wagon train), you have to wait until the big file (a 20 wagon train for example) has passed. If you fragment the 20 wagon train into the individual packets, and send one at a time, then the one packet train has a fair chance to go through together with the packets of the 20 wagons train.
As it works now, you can download your e-mail (50K) while you download this big video file (700GB). You don’t have to wait for the video to download before you can read your mail. Isn’t this great?
This discussion is closely related to the concept of net neutrality. In a condition of neutrality, all packets are equal, and have the same privileges and the same speed of transmission. In a non-neutral situation, a provider might, for example, limit the bandwidth (or make this bandwidth more expensive), for certain kind of packets, for example those related to peer to peer traffic (file exchange between users), or maybe those related to VoIP traffic, for commercial or other purposes.
Let’s dig further in the next section.
Chapter Sections
[pagelist include=”36″]
[siblings]
Figure 1-1-1 does not seem to correspond with what you are talking about in your written text. For example you reference: “As we mentioned, communication paths (most often constituted by physical wires) between computer A and computer F (Figure 1-1) on the Internet are often redundant. Also, these paths are often not direct (unless A and F are in the same room or the same building), but rather contain a number or “relays”.That is, in order for data to travel from A to F, they might be relayed through B, C, and D (Figure 1-1).” However, there is no reference to the word “Computer A,B or C” in that figure.